Automating the deployment of my Hugo site
- Note taken on
Updated post and the cron job script + notes based on an illuminating conversation with R2robot in the Hugo IRC channel ##hugo. IRC rocks.. most of the time.
This website is based off Hugo. The complete source is available as a Git repo at shrysr/sr-hugo. Currently, my only actions are to make changes to an Org source file and export the same via ox-hugo.
Even the export of the subtree or the file via ox-hugo can be automated via the TODO/DONE states. I currently prefer not to do so, but intent to gravitate to that soon.
The website is hosted on a Linode VPS running a Debian OS. Since I started off with a self-hosted Wordpress setup, I have a LAMP stack set up.
While a LAMP stack is not necessary for running a static hugo website, it is still useful for other purposes like hosting multiple wikis or blogs and websites or apps on the same server. Nginx is an alternative to the ‘A’ (in LAMP) for Apache. In case of using Nginx, the general acronym is replaced by an E (as in LEMP). It is also not really necessary to have the ‘P’ (PHP) or M (MySQL) setup if one is not using Wordpress (or other applications that need these) for a Hugo site. Both Linode and Digital Ocean have nice tutorials that take you through the setup step by step.
The idea here is that the website development (including generating content) and testing the website will take place locally and the VPS is only meant to serve the website. i.e direct development of the website on the server will be avoided unless necessary. In a way this mimics production environments, though there are better technical ways to do so. For example, using git branches, or adding additional steps in between like a fetch and a compare and a final test. This is being eschewed at the moment, since I will test the website locally before deploying changes.
Summary of the steps:
- Clone the website repo to the machine I am working on. This is usually a local machine.
- Implement the desired changes while testing that the website works
using the
hugo servecommand in the root of the hugo site directory. - Once satisfied, the changes are consolidated in useful commits and pushed to the github repo. It makes no difference whether the repo is on github or any other git system.
- A cron job is setup on the VPS, to call a script. The script starts
the hugo process with an additional watch flag in the
background. Next it pulls in the git changes and the watch process
will deploy the website to the location set up being served via the
Apache configuration.
- It is generally neither recommended nor required for the user files being served by Apache to be owned by root. Instead, the files can be owned by the user (who can have a login account if needed), and the document root can be owned by a user that is still not necessarily root.
- Note that using an entirely different user may mean installing the necessary SSH keys for that user as well to be able to pull in via git. Technically, if this is a production server, the HTTPS based pulling is sufficient. However, this being a personal server, there are some rare occasions when I want to work directly on the headless server.
- The cron job actually calls a script every 10 minutes, because it is easier to edit a script than write a verbose command in cron.
- The trick of exiting a background process started by the script is to use a trap as described in A Script to Start (and Stop!) Background Processes in Bash.
- My understanding is that the watch process builds the website,
compares it with the destination and will sync only the updates in
any case. If the
-dflag was used alone, it means the website is essentially re-constructed from scratch and pushed each time.- Note that this is yet to be verified. Technically, the hugo watch process would have to build the current website, and then compare it with the destination website to know whether they match. One way to verify this would be check the time stamps of the files in the generated hugo directory. 7
A cron job is usually created using crontab -e. Note that the same
approach can be used to create/edit crontabs for other user using the
sudo -u user crontab -e. Also note that apparently variables like
$HOME do get expanded by cron jobs since these are probably globally
defined.
*/10 * * * * sh /home/username/src/hugo-pull-deploy.sh
#!/usr/bin/env zsh
# Script to git pull hugo site repo and deploy. This script is called by
# a cron job. Replace username with your username. Note that I have
# compiled hugo from the source to obtain a specific version which was
# necessary for my theme and also to maintain parity with my local hugo
# version. This can be added to my path if desired. Since only limited
# commands are run using hugo at the moment, I have not yet done so.
# Setup the trap. This will ensure the background process is killed when
# the script is finished.
trap "kill 0" EXIT
# Hugo project root directory. It's easier to work from here.
cd /home/username/hugo-sr
# Start the hugo watch process in the background to monitor the hugo
# root directory and send updates to the destination, if any.
/home/username/go/bin/hugo -w -d /var/www/html/website.name/public_html/ &
# Pull in the latest from the remote
git pull
# Sleep for good measure though hugo generates the site in seconds
sleep 2m
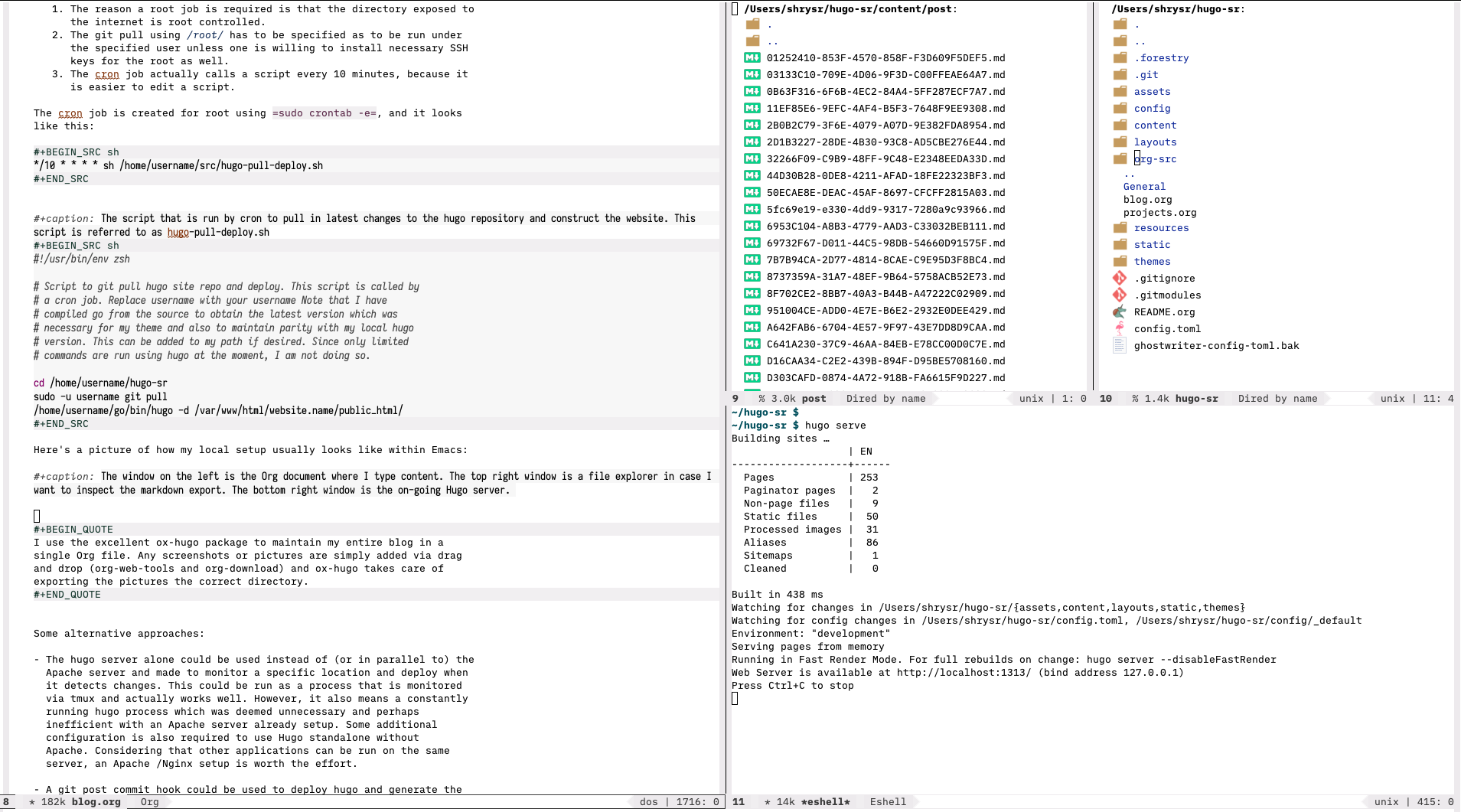
I use the excellent ox-hugo package to maintain my entire blog in a single Org file. Any screenshots or pictures are simply added via drag and drop (org-web-tools and org-download) and ox-hugo takes care of exporting the pictures the correct directory. I doubt it can get too much easier than it is right now. The only thing that would make it easier if I just commit an Org source file, and have an automated process to check whether the site builds as expected or not.
Some alternative approaches:
-
The hugo server alone could be used instead of (or in parallel to) the Apache server and made to monitor a specific location and deploy when it detects changes. This could be run as a process that is monitored via tmux and actually works well. However, it also means a constantly running hugo process which was deemed unnecessary and perhaps inefficient with an Apache server already setup. Some additional configuration is also required to use Hugo standalone without Apache. Considering that other applications can be run on the same server, an Apache /Nginx setup is worth the effort.
-
A git post commit or pull hook could be used to deploy hugo and generate the website. However, I think this approach has more strings attached than using a simple cron job, in the sense that, I want the website generation to be independent of a git commit.
Conclusions
I’ve tested the above and it works satisfactorily. All I have to do at the moment is write my post in Org mode and export via ox-hugo. The deployment is automated, and is reasonably efficient, though there is always scope to make it better.
-
Perhaps introduce a pre-condition check for the hugo command to check whether there have been any changes in the pull at all. One way of doing this is described well at bash - Check if pull needed in Git - Stack Overflow.
-
Enable website deployment with only the commit of an Org file, along with appropriate tests and notifications that the website does build. Perhaps this will need the integration of a CI service, or I wonder if I could have a simple email or message dropped from my VPS, using something like Gotify.
Shreyas Ragavan
Nerd | Technophile | Data Scientist